Google, ever the inventors of new technology and the owners of YouTube.com, have broadened their work into the area of sound effects, specifically through the audio captioning on their YouTube network. Traditionally “closed captions,” which provide text on the screen for those with hearing challenges, provided dialog and narration text from audio. Now, however, Google has rolled out technology that can recognized the .wav forms of different types of sounds to include on their videos, dubbed “Sound Effects Captioning.” They do this to convey as much of the sound impact as possible from their videos, which is often contained with the ambient sound, above and beyond the voice.
In “Adding Sound Effect Information to YouTube Captions” by Scorish Chaudhuri, Google’s own research information blog, three different Google teams, Accessibility, Sound Understanding, and YouTube utilized machine learning (ML) to develop a completely new technology, a sound captioning system for video. In order to do this, they used a Deep Neural Network (DNN) model for ML and three specific steps were required for success: to accurately be able to detect various ambient sounds, to “localize” the sound within that segment, and place it in the correct spot in the caption sequence. They had to train their DNN using sound information in a huge labeled data set. For example, they acquired or generated many sounds of a specific type, say “applause,” to be used to teach their machine.
Interestingly, and smartly, the three Google teams decided to begin with 3 basic sounds that are listed as among the most common in human created caption tracks, which are music, applause, and laughter: [[MUSIC], [APPLAUSE], and [LAUGHTER]. They report that they made sure to build an infrastructure that can accommodate new sounds in the future that are more specific, such as types of music and types of laughter. They explain a complex system of created classifications of sounds that the DNN can recognize even multiple sounds are playing, meaning the ability to “localize” a sound in a wider variety of simultaneous audio. Which, apparently they were successful in achieving.
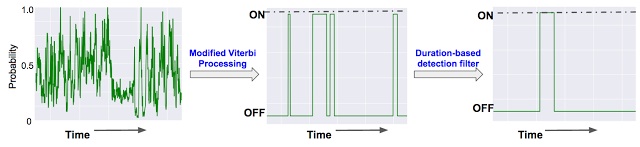
After being able to recognize a specific sound such as laughter, the next task for the teams was to figure out how to convey this information in a usable way to the viewer. While they do not specify which means they use to present the captioning, the different choices seem to be: have one part of the screen for voice captioning and one for sound captioning, interleave the two, or only have the sfx captions at the end of sentences. They were also interested in how users felt about the captions with the sound off and interestingly, discovered that viewers were not displeased with error, as long as the majority of time the sound captions communicated the basic information. In addition, listeners who could hear the audio did not have difficulty ignoring any inaccuracies.
Overall this new system of automatically capturing sounds to display as closed captioning via a computer system as opposed to a human by hand looks very promising. And, as Google has shown time and time again, they don’t seem to have a problem with the constant evolution of products that succeed and that users value. They stress that this auto capturing of sound increases specifically the “richness” of their user generated videos. They believe the current iteration is a basic framework for future improvement in sound captioning, improvements that may be brought on by user input themselves.